5D Parallelism for Transformer Training
completeBuilt the parallel training stack for a GPT-style model as a capstone for a hands-on distributed systems workshop, implementing data, tensor, pipeline, context, and expert parallelism from scratch, then benchmarked throughput, memory, and convergence across 1–8 GPU configurations.
Training Parallelism, From Single-GPU Baseline to 5D Distributed Runs
Capstone project for a 5D Parallelism Workshop — implementing and benchmarking five distributed training strategies for a GPT-style Transformer from scratch.
I implemented multiple parallelism strategies and benchmarked how each technique affects throughput, memory, and training dynamics across individual and combined configurations.
The Problem
Training large Transformers is limited by GPU memory, communication overhead, and poor utilization when work is split naively. This project explored how modern LLM training systems break the model, batch, sequence, and expert dimensions across multiple GPUs — implementing each technique from scratch rather than relying on a framework abstraction.
My Role
I built the full parallel training stack as the workshop capstone:
- Data parallel scaling baselines across 1, 2, 4, and 8 GPUs
- Tensor parallel column/row linear layers with all-gather/all-reduce communication
- Pipeline parallel model partitioning and micro-batch scheduling
- Context parallel ring attention for sequence sharding
- Expert parallel MoE routing with top-k gating and load balancing
- Combination runs: TP+PP+EP and TP+CP
Technical Implementation
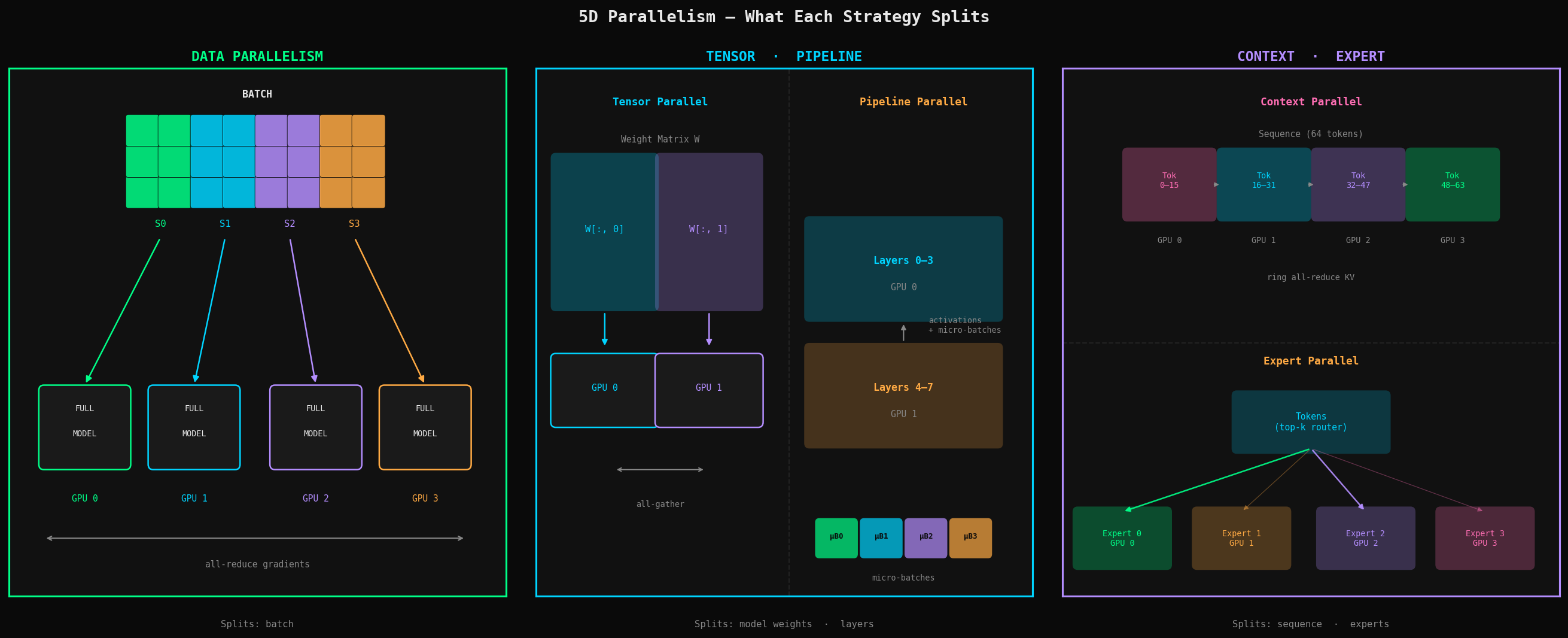
| Technique | What It Splits | Key Implementation | What It Demonstrates |
|---|---|---|---|
| Data Parallelism | Batch | Replicated model + distributed batches | Scaling throughput with more GPUs |
| Tensor Parallelism | Matrix dimensions | ColumnParallelLinear and RowParallelLinear | Splitting Transformer matmuls across devices |
| Pipeline Parallelism | Layers | PipelineStage + micro-batches | Reducing idle time across model stages |
| Context Parallelism | Sequence length | Ring attention over KV chunks | Long-context attention without full-sequence memory |
| Expert Parallelism | MoE experts | Top-k router + distributed expert execution | Conditional compute and expert sharding |
Throughput Comparison
Results
Steady-state averages from steps 1–48, excluding initialization and final validation overhead.
| Run | Parallelism | Avg Tok/Sec | Final Val Loss | Notes |
|---|---|---|---|---|
gpu1_tp1_pp1_cp1_ep1 | DP=1 baseline | ~266K | 8.6988 | Single-GPU baseline |
gpu2_tp1_pp1_cp1_ep1 | DP=2 | ~531K | 8.6533 | Near-linear DP scaling |
gpu4_tp1_pp1_cp1_ep1 | DP=4 | ~1.06M | 8.6297 | Continued DP scaling |
gpu8_tp1_pp1_cp1_ep1 | DP=8 | ~2.10M | 8.6034 | Fastest pure throughput run |
gpu8_tp2_pp1_cp1_ep1 | TP=2, DP=4 | ~1.16M | 8.6929 | Tensor-parallel matmul split |
gpu8_tp1_pp2_cp1_ep1 | PP=2, DP=4 | ~531K | — | Pipeline schedule benchmark (logging artifact) |
gpu8_tp1_pp1_cp2_ep1 | CP=2, DP=4 | ~83K | 8.6118 | Ring attention has high communication cost |
gpu8_tp1_pp1_cp1_ep4 | EP=4, DP=2 | ~363K | 8.9291 | MoE routing and expert sharding |
gpu8_tp2_pp2_cp1_ep2 | TP=2, PP=2, EP=2 | ~150K | 8.9118 | Combined model/expert parallelism |
gpu8_tp2_pp1_cp2_ep1 | TP=2, CP=2, DP=2 | ~124K | 8.7077 | Combined tensor + context parallelism |
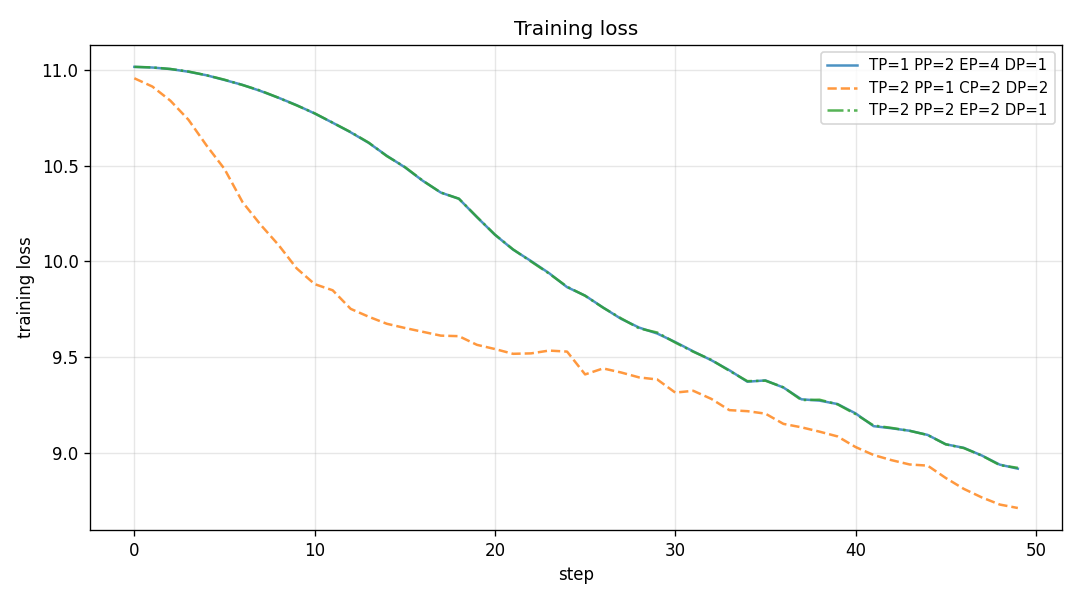
Training Loss
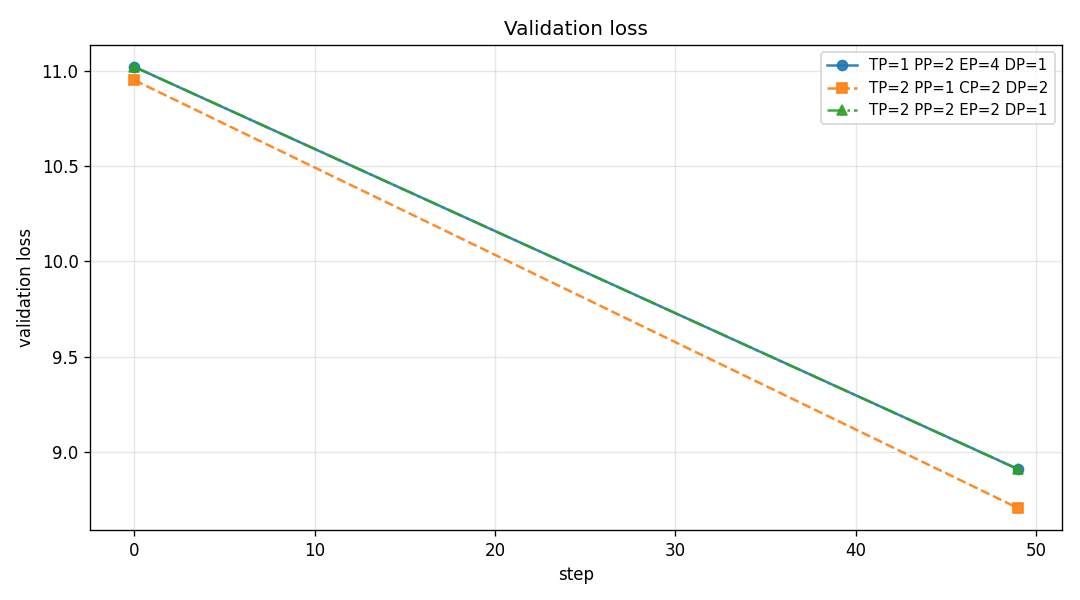
Validation Loss
Key Takeaways
The most important result was not simply which run was fastest, but how each parallelism strategy introduced a different tradeoff:
- Pure data parallelism achieved the highest token throughput because it minimized communication complexity — the replicated model pattern pays off when the model fits on a single device.
- Tensor parallelism reduced per-rank model work but introduced collective communication at every matmul boundary.
- Pipeline parallelism exposed the cost of pipeline bubbles and micro-batch scheduling overhead.
- Context parallelism enabled sequence sharding but ring attention communication dominated at this model scale.
- Expert parallelism demonstrated conditional compute and routing overhead, amplified when combined with other model-parallel strategies.
Technical Stack
| Layer | Tool |
|---|---|
| Framework | PyTorch Distributed (NCCL backend) |
| Parallelism | Custom DP, TP, PP, CP, EP implementations |
| Model | GPT-style Transformer (slim) |
| Hardware | Up to 8 GPUs |
| Visualization | matplotlib |